本篇文章将从如何定义 Git 大仓库,大仓库如何产生,大仓库的负面影响等方面讨论起,然后介绍几款目前针对大仓库的处理工具,并讨论它们的优缺点,然后谈谈我们今天要介绍的新工具 git repo-clean 的一些设计目标,并重点介绍它的设计原理。
作为国内最大的代码托管平台,Gitee 每天都有大量不同行业的人在上面围绕 Git 仓库进行各种 Git 操作实践。
但是我们经常收到用户的帮助请求,他们的问题往往是其 Git 仓库变得非常大,这影响了他们对仓库做进一步的操作,甚至会导致开发进度落后。
实际场景:
场景一:
用户不小心使用
git add .将当前工作区中的所有文件加入到 Git 仓库,并做了提交,但是后来意识到有些文件并不是想要的,如build/、ThirdPart/、vendor/等目录下的文件,于是想删除掉之前的提交中的部分文件。一般情况下,可以使用git reset或者git revert回退当前的bad commit到它的前一次commit。但是,由于已经提交了很多正常的有用的commit,这个时候再回退就需要小心了,因为所有bad commit之后的所有正常提交也会被回退。场景二:
在一个成熟的项目中经过多年的迭代,项目的功能变得与以前非常不同,不断地代码迭代也使得 Git 仓库变得臃肿,再加上在用 Git 管理项目的前期由于使用的不成熟,向仓库提交了很多不必要的文件,这些文件长期存在,而且如果对一个大文件进行过多次修改,每个版本都会完整保存在仓库中,则体积也会成倍增长。之后推送到服务端仓库,也会占用相当大的服务端仓库资源。同时,在协作开发的情况下,意味着每个人都会克隆一个巨大的仓库到本地,而且由于数据量很大,该过程变得很慢。
问题:
基于以上场景,可以归纳出 Git 仓库的几种常见的问题:
向仓库中提交了大量不必要的文件。如:项目编译过程文件,第三方库文件,多媒体文件等。这导致 Git 仓库的提交文件被污染。
向仓库中提交的单个文件非常大。假如提交了一个 100M 的文件,一方面平台会限制用户推送单个文件大小超过 100M 的文件;另一方面,如果多次修改过这个文件,仓库中将会存在多个版本,比如经过 10 次修改,每个版本大约还是 100M,那仓库就会因为这个文件,体积变为
10 * 100M,这样仓库总的大小也会变得巨大,也将超过推送限额。
以上都属于是 Git 大仓库问题,根据经验法则,大仓库的衡量维度包括:
单个文件是否过大
文件数量是否过多, 如数量超过 100k
提交数量是否过多,如数量超过 100K
分支数/标签数是否过多,如数量超过 10K
子模块是否过多,如超过 25 个子模块
关于 Git 大仓库的详细说明,可见这篇文章 [1]。
以上衡量标准并不是固定的,只是根据经验所得,是一种参考值,其衡量值往往随着电脑的性能,系统的类型,以及 Git 的版本不同而不同。
但是根据这种衡量标准,我们大致能知道怎么样的仓库才算得上大仓库。
我们收到的大仓库问题反馈一般集中在前两种。通常,当出现仓库数据过大的信号后,用户一开始往往会选择删除仓库当前工作区下的文件,而忽略了 Git 仓库是分为工作区,缓存区,对象存储区的结构。当文件提交后,不仅工作区存在该文件,对象存储区也存在该文件,所以只删除工作区的文件,虽然肉眼看不见文件了,但其实它还是存在仓库中,通过一些 git 命令很容易将它恢复到当前工作区。这说明仓库体积并没用有效的减少。
一方面,Git 是生来是为源代码文件而设计和优化的,而源代码文件一般都不会很大,对于大仓库,Git 的很多操作的性能产生非常大的影响,如果大仓库中问非常多,那么在有遍历操作的 git 命令的时候就非常耗时;另一方面,Git 是分布式的,一个仓库通常包含所有的修改版本、提交历史。大仓库的数据存储和传输会有一定压力,比如传输很慢,传输超时,或者存储空间不足导致传输失败等。
我们很多时候很难避免制造 Git 大仓库,所以这些问题很容易出现。对 Git 的操作比较熟悉的人,会在项目刚开始的时候,通过 .gitignore 文件 [2]来管理提交到仓库的文件。
在 Gitee 上新建仓库时,也会提供 .gitignore 模板文件:

如果仓库中没有这个文件,需要手动新建。
这个文件的作用是将指定类型,或者指定目录下的文件忽视掉,Git 就不会将这些文件加入到仓库中,从而保持仓库干净。
使用 .gitignore 管理仓库文件只是防止仓库污染、体积膨胀的手段之一。
另外一种手段是使用 Git LFS 专门来管理仓库大文件,从而避免仓库体积膨胀。
该功能的原理是,使用专门的大文件存储服务器来管理仓库中特定的大文件,而本地仓库只管理大文件的指针。详情可参考:Git LFS 操作指南 [3]。
如果是仓库中已经存在大量非必要大文件而导致仓库体积膨胀,那么如何解决呢?其实已经有人做出了一些工具,来试图解决此类问题。
我们先来看下几种常见的工具的对比:
同类工具对比:
git-filter-branch [4]
特点:
Git 内部自带的命令,只要有 Git 环境,就能使用这个工具。
使用示例:
1 | $ git filter-branch --tree-filter 'rm -f path/to/large/file' --tag-name-filter cat -- --all |
问题:
使用起来比较复杂;
如果不确定大文件,需要先使用其它命令手动扫描仓库中存在的大文件;
处理过程特别慢 [5]!;
如果存在特殊文件名,特殊文件路径,可能会出错,甚至误删文件;
删除文件、重写历史之后,可能旧的和新的历史记录都存在,导致仓库体积反而变大 [6]。
git-filter-repo [7]
特点:
git filter-branch 的官方替代,官方推荐使用该工具来代替原生 git-filter-branch 命令。
速度快,功能多,使用灵活。
使用示例:
1 | $ git filter-repo --path bigfile.zip --path big/files/dir/ --invert-paths |
问题:
需要删除的文件可能不在当前工作区,而是在历史提交中,用户无法直接提供文件名、文件 ID 进行删除;
依赖 Python 环境。
BFG Repo-Cleaner [8]
特点:
速度快,使用比较简单。
使用示例:
1 | $ java -jar bfg.jar --strip-blobs-bigger-than 100M my-big-repo.git |
问题:
不会处理最新的 commit(HEAD commit);
会在所有被处理的 commit 信息中加入额外的信息。如:
Former-commit-id: xxxxx,特别是如果多次运行该命令,则会在这些 commit 中加入多条额外信息,这会污染 commit 信息;处理之后会在 HEAD commit 中加入很多额外信息;
对松散对象没有做处理;如果松散对象是要删除的大文件,则不会成功;
需要额外手动进行 GC 操作;
依赖 Java 环境。
git-siezer [9]
特点:
对 Git 仓库中的数据指标进行详细的统计。
使用实例:
1 | $ git sizer --threshold=0 |
问题:
只是对仓库的数据信息做概括统计。如:总的 commit 数量,总的文件(blob)数量,最大的单个文件等,不能告诉用户最大的 N 个文件,不能进行文件删除、历史重写。
git-repo-clean 设计目标:
通过对以上工具的特点、问题进行总结,我们试图开发出一款工具,解决以下问题:
纯命令行方式对有些用户不太友好,并且使用说明都是英文,阅读英文使用文档比较困难
没有自动对仓库进行备份,由于可能误操作,丢失仓库数据
对仓库历史文件不太了解,无法准确知道需要删除哪些文件
删除过程太慢。
这款工具就是:git-repo-clean [10]。
总的来说,git-repo-clean 具备以下 优势:
使用简单。支持交互模式,用户操作起来比单纯的命令行方式更简单。
支持扫描模式。当对历史提交文件不太了解时,可以选择先扫描仓库,只需提供文件类型、大小、数量即可扫描出目标历史文件,再进行删除(交互模式下,也会使用扫描模式),弥补了
git-filter-branch的缺点。支持直接指定文件进行删除。
支持删除指定目录下的所有文件(包括目录本身),及其提交记录。
速度快。从
v1.2.0开始,git-repo-clean的速度可以达到与git-filter-repo同级别速度。无其它依赖。源码使用 Golang 实现,通过交叉编译,最终可执行程序可在多平台兼容,不需要依赖特定的语言环境。
本地化。有中文文档,软件使用界面支持本地化。
git-repo-clean 技术原理:
一般来说,我们要创建一个 Git 仓库,需要以下操作:
1 | $ git init mini-repo && cd mini-repo |
Git 内部提供了两个命令: git-fast-export, git-fast-import, 他们分别的作用是将 Git 仓库数据(.git/objects)导出为特定格式的 元数据,然后流式读取这种特定格式的元数据,于是就成一个完整的 Git 仓库。
任何符合格式的完整的元数据,输入给 git-fast-import 都能创建一个 Git 仓库。
我们先来看下一组最小完整的 Git 元数据:
1 | blob # blob类型,即文件 |
通过这组元数据,使用 git fast-import 命令,就能创建出一个完整的仓库,里面包含:
一个文件,文件大小是 32 Bytes, 内容是:
FILE: this is the file content.一个分支,分支名为
master一个 commit 提交,表示对 README 文件的修改。提交信息是:
COMMIT: this is the commit message. The file name will be README
口说无凭,我们来看下这组元数据实际怎么生成一个完整 Git 仓库的。
首先需要在一个空的 Git 仓库中进行操作,然后将上述元数据输入到 git fast-import 中。
假设上述元数据存放在文件 meatadata 中。
接下来,具体操作如下:
1 | $ git init fake-repo && cd fake-repo |
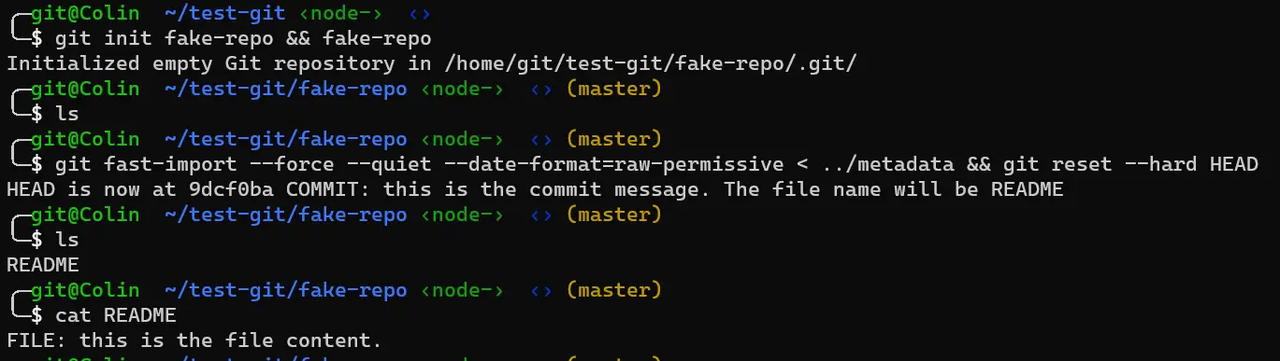
成功之后,刚创建的新仓库 fake-repo 下就有了一个 README 文件,一个 commit 提交,一个 master 分支:
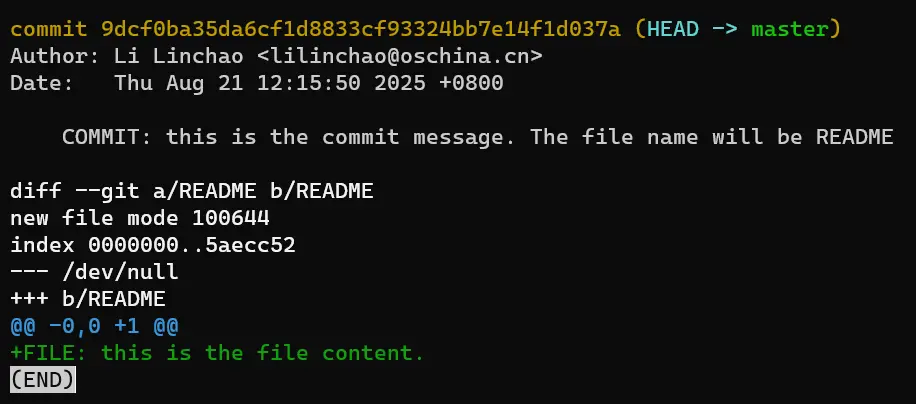
README 文件信息和 commit 信息都是根据元数据 metadata 中的定义而来,我们可以任意修改。
可以说,Git 元数据是对 Git 仓库中的底层数据(blob, tree, commit, tag)进行结构化表示。
那么,如果我们想对一个现存的 Git 仓库进行有目的修改,可以先获得该仓库的元数据,然后进行相应操作。
1 | 如何获得一个 Git 仓库的元数据呢? |
那就是前面提到的 git fast-export 命令。
git fast-export 命令可以接受很多参数,比如:
--show-original-ids用于在输出中加入每个数据类型的原始 hash ID, 这个对于重写 commit 历史,或者通过 ID 裁剪 blob 有帮助。--reencode=(yes|no|abort)用于处理 commit 信息中的编码问题, yes 表示将 commit message 重新编码为UTF-8。--no-data会在输出中省略blob类型数据。
具体应该使用什么参数,可以根据修改的目的来调整。
例如, 使用 --show-original-ids, --reencode, --use-done-feature, --all 选项时的输出如下:
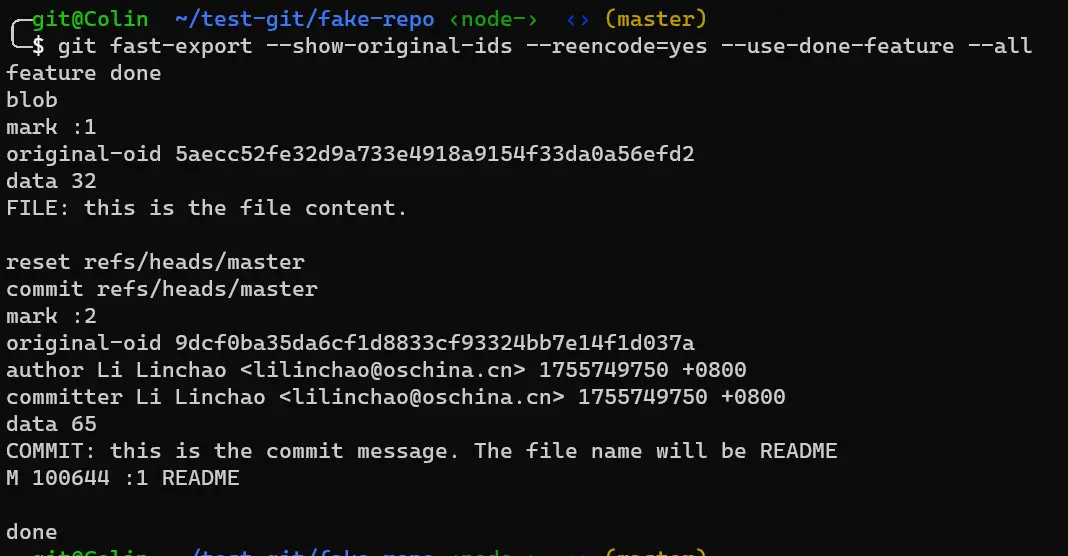
到目前为止,我们已经知道如何获取仓库元数据,也知道怎么根据元数据生成一个新的仓库,那么如果我们想要对仓库进行修改,只需要在这个过程中进行 元数据过滤 即可。
所以 git-clean-repo 的大致流程如下:
1 | git-fast-export |
要解析的元数据中存在不同的数据类型, 它们的格式为:
blob
1 | blob |
其中,mark id 的格式为 :n, 比如::2
reset
1 | reset [ref name] |
commit
1 | commit [ref name] |
其中,filechanges 格式如下:
1 | [type] [file-mode] [file-id] [file-path] |
tag
1 | tag [tag name] |
git-fast-export 的输出中,mark 标号(mark ID)比较关键,它是每种数据的原始顺序,以及引用时的索引号。
每当从 git-fast-export 输出流中解析到一种完整的数据,需要对数据中我们关心的字段进行检查。
比如,我们要根据文件大小来过滤掉仓库中的大文件,在解析到 blob 数据类型时,当获取到 blob size 信息时,可以与我们的预期大小进行对比,如果超过预期大小,则可以把这个 blob 标记为可删除状态,整条 blob 数据都不会输入到 git-fast-import 中,这样就做到了文件删除, 同时记住这个 blob 的 mark ID, 后续继续流式输出时,只要涉及到引用该 mark ID 的 commit,需要将其中的 filechanges 进行修改。如果一个 commit 的 filechanges 删减到为零,则整条 commit 需要丢掉,这样就实现了与删除文件相关的 commit 的更新。
我们用一组示意图进行说明:
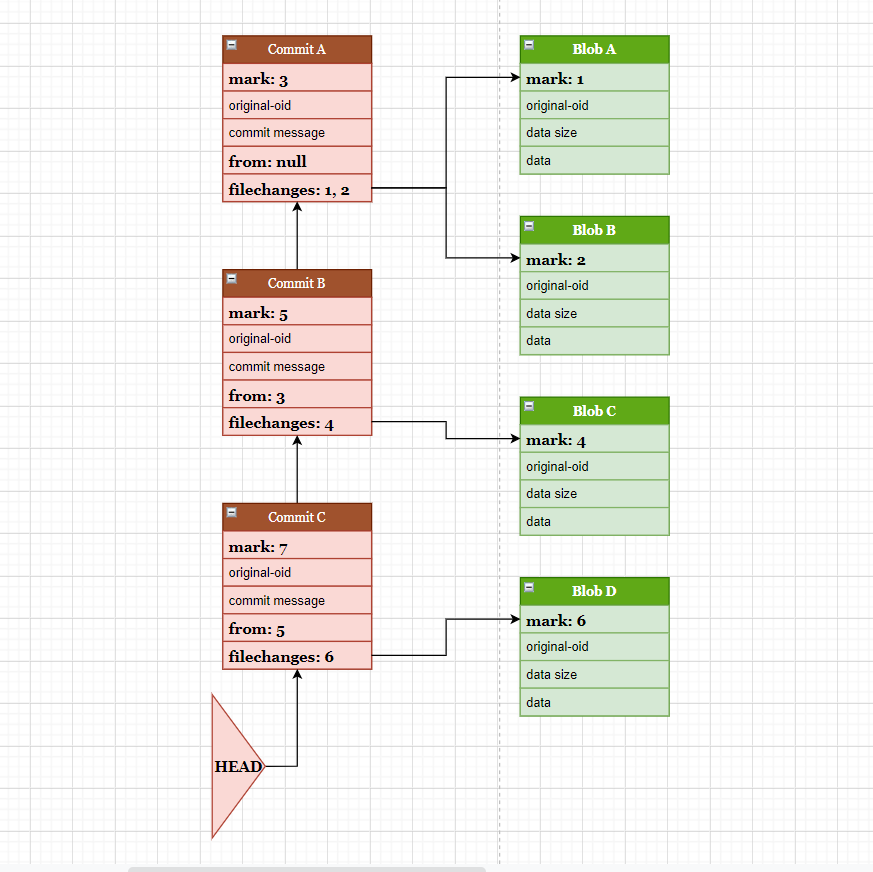
上图表示一个简单仓库中元数据的组织方式,为了方便展示,省略了 tag、引用等数据结构,只突出文件及其提交。
图中有 4 个文件:Blob-A, Blob-B, Blob-C, Blob-D。
产生了 3 个提交:Commit-A, Commit-B, Commit-C。
Commit-A 提交涉及文件 Blob-A, Blob-B, Commit-B 提交涉及文件 Blob-C, Commit-C 提交涉及文件 Blob-D。
使用 git-fast-export 导出仓库的元数据时,是按数据的先后顺序流式输出的,这个顺序即是 mark ID 的顺序。所以,本示例图中的数据顺序就是:

现在的目标是要删除文件 Blob-C,以及它涉及到的提交。
删除的方式可以从文件的几个维度入手:
文件的名称
文件的 ID, 即图中的
original-oid文件的大小,即图中的
data size
无论哪种方式,目的是要先筛选出目标文件,然后进行标记。
所谓标记,可以简单的认为是将它的 mark ID 从原有的序号系统中剔除,即标记为 0。
当 blob 的 mark ID 标记为 0 之后,后续解析到的 commit 时,会检查其中的 filechanges,标记为 0 的 filechange 会被移除,如果最终的 filechanges 数量为 0,说明该条 commit 所涉及到的所以修改文件都已经被删除,则整条 commit 也应该被删除。
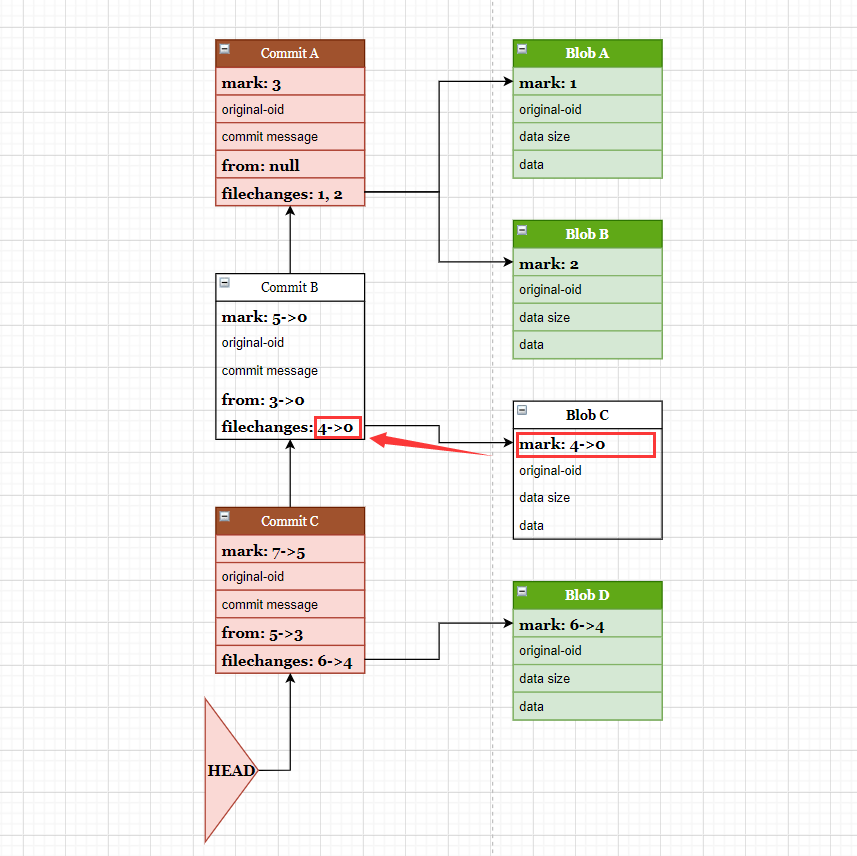
在 Blob-C, Commit-B 标记为删除之后,后续所有数据的 mark ID 需要相应的改变, 以便保持一致。
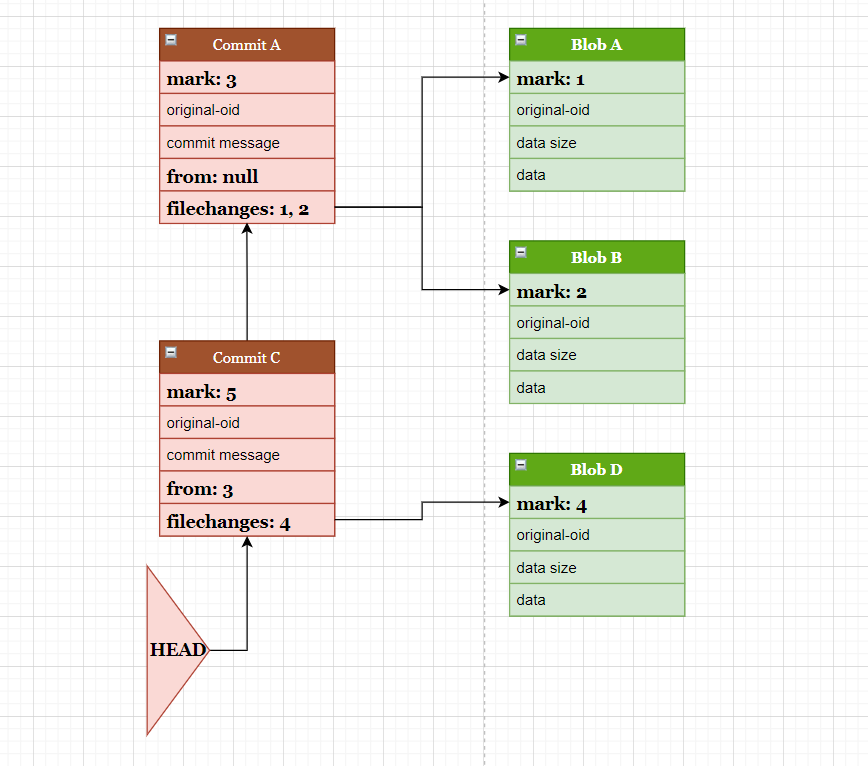
如 Commit-C 的 mark ID 变为 5, parent commit(from) 指向 3,filechanges 指向 4。
这样就完成了删除文件 Blob-C,以及其涉及到的 Commit-C。
对于多文件,或者多分支删除,因为整个过程的数据是流式输出,所有的数据都按 出场顺序 有自己的唯一编号,所以处理起来是一样的。
以上就是 git-repo-clean 的内部原理。
使用建议:
不管是哪种重写历史的工具,都是对仓库进行破坏性操作,有些事项需要特别注意。
事项 1:备份你的原始仓库
git repo-clean在交互模式下,会询问用户是否进行备份,如果选择是,则会自动帮用户进行仓库备份。
事项 2:重写历史会改变 commit 的 ID 值,可能会影响现存 PR,所以建议先关掉或者合并现存 PR。
事项 3:在本地仓库重写历史并强制推送到远程仓库之后,应该告知所有使用该仓库进行协同开发的人,需要同步远程仓库,避免再将本地旧的历史提交到远程。
后续:
在 v1.3.0 中我们已经实现将大文件转换为 Git LFS 文件的功能。